
2026年3月26日(現地時間)- 生成AIプラットフォーム「ComfyUI」の開発チームはシステムRAMの使用量を大幅に削減し、限られたメモリ環境下でも大規模なモデルを効率的に実行可能にする新しいメモリ最適化システム「Dynamic VRAM」を発表しました。
このアップデートは、Windows と Linux 環境の Nvidia ハードウェア向けに、すでに約1か月程前から ComfyUI の安定版に導入されています。(WSLサポートは現在予定されていません)ハードウェアメモリの価格が高騰し続ける中、この新機能は、メモリ容量に制約のあるローカル環境のユーザーにとって、OOM(Out‑Of‑Memory)エラーの解消やワークフロー全体の高速化といった面で大きな助けとなります。
「Dynamic VRAM」がもたらす主な改善点
Dynamic VRAM は、既存の設定を微調整するような仕組みではなく、モデルのウェイト(重み)の扱い方を根本的に変更するシステムです。公式発表では、次のような具体的な改善点が示されています。
- システムRAM使用量の削減: 複雑なワークフローを実行する際に必要となる従来のRAMの量が顕著に減少します。
- OOMエラーの解消: ウェイトのオフロードが不十分なために発生していたメモリ不足によるクラッシュが解消されます。
- ロード時間の高速化: 初期モデルの読み込みやLoRAの適用が、一部のケースで大幅に高速化されます。
- ページングの防止: 物理RAMの容量を超えるモデルを実行する場合でも、OSの低速なページファイル(仮想メモリ)に依存することなく動作可能になります。
- VRAM使用率の向上: GPUのVRAM使用率が以前より高く表示される場合がありますが、これはシステムが最速のメモリをより効果的に利用している正常な状態を示しています。
- 開発と処理の簡素化: 以前のシステムでは、推論前にモデルが消費するメモリ量を予測し、OOMを防ぐために十分な空き容量を確保する必要がありましたが、Dynamic VRAMの導入によりこれらの事前の調整が不要になりました。
パフォーマンスベンチマーク
ComfyUIはこれまでもコンシューマー向けハードウェアでモデルを実行する上でメモリ効率に優れていましたが、新たな最
ComfyUI はこれまでもコンシューマー向けハードウェアでのメモリ効率に優れていましたが、今回の最適化により、さらに高速な動作が確認されています。公式が提示しているベンチマークは次のとおりです。
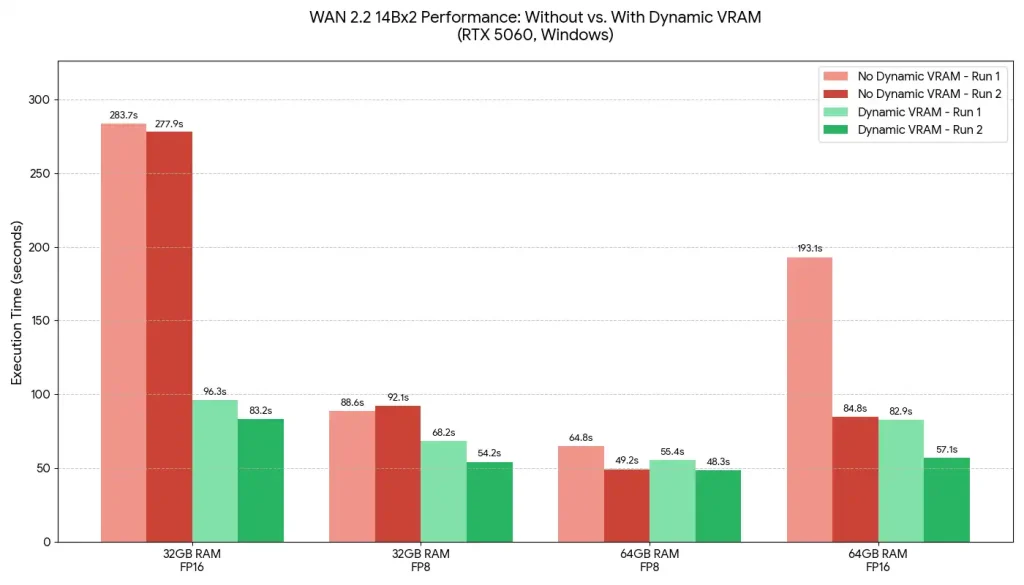
動画生成ワークフロー (WAN2.2)
2×14B の fp16 / fp8 モデル(320×320×81 フレーム)を使用し、RTX 5060・32GB/64GB RAM を搭載した Windows 環境でテストが行われました。拡散モデルの合計サイズは fp16 で 56GB に達しますが、それでも安定して動作することが確認されています。
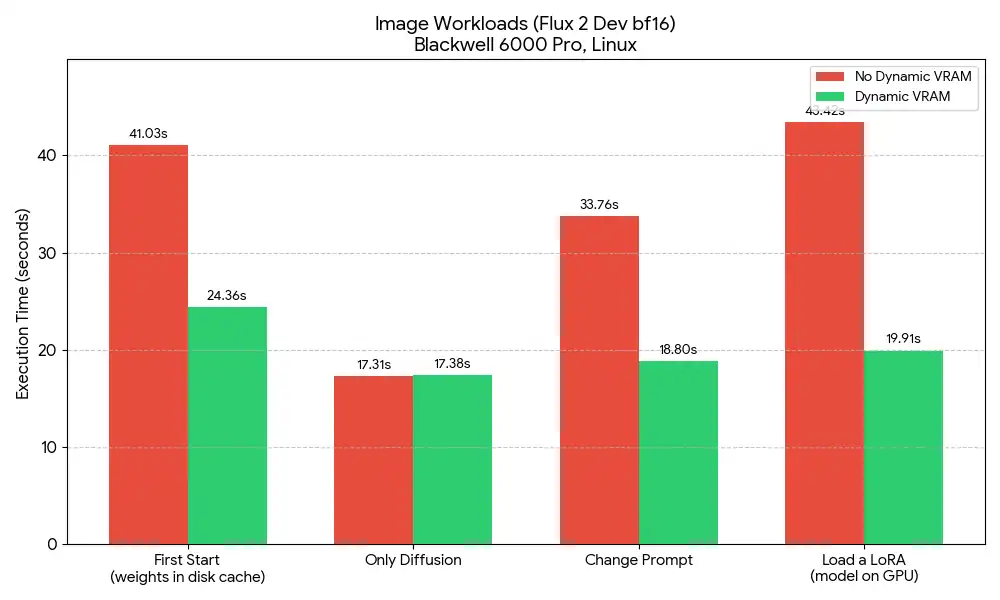
画像生成ワークフロー(Flux 2 Dev)
デフォルトワークフローに加え、bf16 テキストエンコーダーと拡散モデルを使用し、Linux(Blackwell 6000 Pro)環境でテストが実施されています。
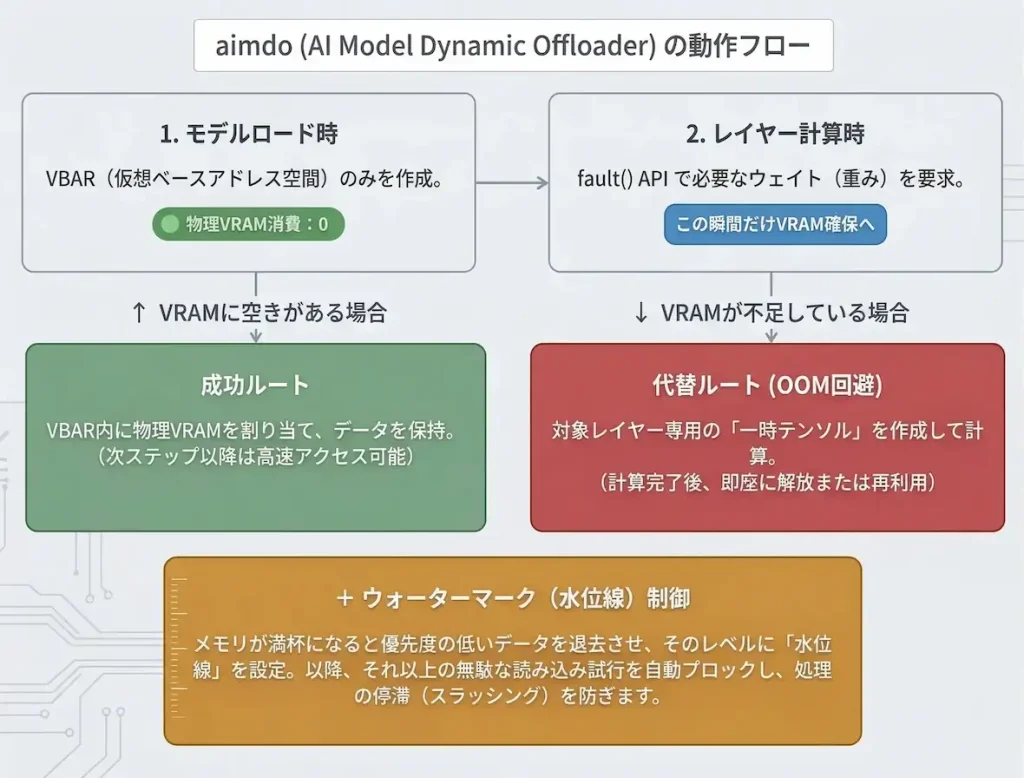
Dynamic VRAMの中核システムの仕組み
Dynamic VRAMを支える中核モジュールである「AI Model Dynamic Offloader (通称: aimdo)」は、PyTorch標準のVRAMアロケーターがメモリ逼迫状態に陥った際に、オンデマンドでモデルのウェイトをオフロードする専用のカスタムアロケーターとして機能します。
その詳細なメカニズムは以下の通りです。
- VBAR(仮想ベースアドレスレジスタ)の活用
モデルを読み込む際、システムは「VBAR」を作成します。この時点では物理的なVRAMは一切消費されず、実質的に無制限なGPUの仮想アドレス空間のみを使用します。tensors(テンソル)はこのVBAR内に割り当てられますが、最初は未割り当ての状態であり、通常の方法でアクセスしようとするとセグメンテーション違反(エラー)が発生します。
- ジャストインタイムのメモリ割り当て:fault() API
全てのデータを事前に読み込むのではなく、計算に特定のテンソルが必要になったまさにその瞬間に、カスタムの fault() API を通じてtensorsが「フォールトイン」されます。物理VRAMが実際に消費されるのは、この処理の瞬間のみとなります。
- VRAMの空き状況に応じた柔軟な対応
fault() API でウェイトが要求された際、メモリの状況に応じて2つのシナリオが実行されます。
- 十分なVRAMがある場合(成功): ウェイトのためのVRAMが確保され、データが入力されます。以降のステップでは即座にそのウェイトを利用できるため処理が高速に保たれます。また、システムのメモリが逼迫した場合は、サンプリングの途中であっても即座に解放することが可能です。
- VRAMが不足している場合(失敗): 従来のシステムのようにOOMでクラッシュすることはありません。代わりに、対象のレイヤーでの実行のみに使用される一時的なGPU tensors を割り当て、必要なウェイトデータをコピーして処理を行います。この一時 tensors は、レイヤーの実行後にすぐ解放されるか、他のオフロードされたレイヤーのために再利用されます。
- 「ウォーターマーク(水位線)」による優先度管理
システムが全ウェイトを常に読み込もうとして失敗を繰り返す「スラッシング」と呼ばれる状態を防ぐため、厳格な優先度とウォーターマークの仕組みが採用されています。現在アクティブなモデルには最高の優先度が与えられ、必要に応じて優先度の低いウェイトを強制的にVRAMから退去させます。
退去が発生すると、システムはそのレベルに「ウォーターマーク」を設定します。それ以上のウェイトは以後の fault() API で自動的に失敗扱いとなるため、VRAMが満杯の状態で無駄に読み込みを試みる計算リソースの浪費をスムーズに防ぎます。
注意:記事内で解説されている「ウォーターマーク(水位線)」は、純粋にメモリ管理の閾値を示すコンピュータサイエンスの専門用語です。生成画像に電子透かし等のトラッキング情報が埋め込まれるわけではありません(※公式ブログのコメント欄でもこの点に関する誤解と議論がありました)。
新しいRAM管理の挙動とOS側の見え方
ComfyUI 独自の新しい safetensors ローダーは、より効率的なファイル展開方式を採用しています。
モデルファイルは「未コミット(コミットされていない)ファイルバックメモリ」としてマッピングされ、PyTorch モデルへディープコピーされるのではなく、ポインター参照によって割り当てられます。これにより、新しい環境ではモデルの読み込みがほぼ瞬時に完了します。
WindowsとLinuxにおけるタスクマネージャーの違い
このメモリは「未コミット」状態であるため、OSはシステムの安定性を維持するために、いつでもこのメモリを回収(再利用)する権限を持っています。
- Windowsの場合: タスクマネージャー上ではRAM使用量が低下していないように(高く)見えることがあります。これはComfyUIが高速化のために可能な限りウェイトをキャッシュに保持しているためです。しかし、他のアプリケーションがメモリを必要とした瞬間、OSは即座にその領域をComfyUIから回収します。その後ComfyUIが再びそのウェイトを必要とした場合は、OSが自動的にディスクから再読み込みを行います。
- Linuxの場合: システムモニターではRAM使用量が非常に低く表示される傾向があります。Linuxは未コミットのRAMを使用量としてカウントせず、「ディスクキャッシュ」として扱うためです。
また、ComfyUI はモデルを VRAM から RAM へアンロードする処理を行わなくなりました。未コミットメモリの割り当ては、ワークフロー実行中を含め、モデルが存在する間ずっと保持されます。
これにより、PCIe や DDR バスのトラフィックが削減されるだけでなく、複数モデルを切り替えるワークフローで頻発していた「アンロード時の RAM 枯渇」や、それに伴うページファイル(仮想メモリ)の大量使用を避けられます。VRAM が解放されると、モデルはすぐに前述の「未コミット」状態へ戻り、必要なときに即座に再利用できるようになります。
今後の開発ロードマップ
ComfyUI開発チームはこのシステムの継続的な改善を予定しており、今後の計画として以下を挙げています。
- 報告されたパフォーマンスに関するバグやリグレッション(機能退行)への対応。
- AMD製GPUおよびその他のハードウェアのサポート実装。
- ノード間の中間値をスマートに解放したり、データサイズを小さくする実験的機能(–fp16-intermediatesなど)による、全体的なRAMフットプリントのさらなる削減。
- ディスク読み込み速度のさらなる最適化。高速なNVMe SSDを使用している環境において、モデルや設定次第で速度低下を起こさずに完全なディスクオフロードを実現する可能性の追求。
利用について
ComfyUI を最新版に更新するだけで、Dynamic VRAM が自動的に有効になります。特別なノード追加や設定ファイルの編集は不要です。
今回のアップデートは、ユーザーが複雑な設定を行わなくても効果が得られるよう設計されていますが、最大限に活用するために、次のポイントを押さえておくことをおすすめします。
- 従来の起動引数の見直し:これまで OOM(メモリ不足)対策として
--lowvramや--medvramを使っていた場合、Dynamic VRAM の自動管理と競合し、逆にパフォーマンスが落ちる可能性があります。まずは余計な引数を外した「デフォルト状態」で動作を確認してください。 - 正しいパフォーマンスの測り方:記事でも触れられているように、Windows のタスクマネージャーの RAM 使用量や、コンソールの「it/s(1 秒あたりのステップ数)」だけで性能を判断するのは 正確な評価方法とは言えません。本当に見るべきなのは、生成開始から最終的な画像・動画が出力されるまでの「合計完了時間」です。
Dynamic VRAM に関連すると思われる問題が発生した場合は、GitHub で Issue を作成し、ログ全体・使用ワークフロー・ハードウェア構成・OS 情報などを添えて報告すると、今後の改善に役立ちます。
Dynamic VRAM in ComfyUI: Saving Local Models from RAMmageddon


コメント