NVIDIAより、GPUコンピューティングプラットフォームの最新版であるCUDA 13.2がリリースされました。
今回のアップデートでは、NVIDIA CUDA Tileがコンピュート機能8.x(NVIDIA AmpereおよびAda)、10.x、11.x、そして最新の12.x(NVIDIA Blackwell)アーキテクチャでフルサポートされました。今後のCUDA Toolkitのリリースでは、Ampere以降のすべてのGPUアーキテクチャが完全にサポートされる予定です。
ここでは、、3DCGやシミュレーション分野における開発効率や計算パフォーマンスの向上にも寄与する、CUDA 13.2の主な新機能と改善点を紹介したいと思います。
CUDA Tileとは
NVIDIA CUDA Tileは、NVIDIA Tensorコアにおけるポータビリティ(移植性)を向上させることを目的とした、タイルベースのGPUプログラミングモデルです。
最適化されたタイルベースのカーネルの作成を簡素化することで、NVIDIAプラットフォーム全体でGPUのピークパフォーマンスを容易に引き出せるように設計されています。内部的には「CUDA Tile IR(中間表現)」と呼ばれるタイルプログラミング用の仮想命令セットを基盤としており、このプログラミングモデルをPythonの構文を用いて直感的に記述・最適化できるようにしたものが、後述するcuTile Pythonとなります。
NVIDIA CUDA Tileについてのより詳しい情報はこちらから確認できます。
cuTile Pythonの機能拡張
CUDA TileプログラミングモデルをPython環境で利用するためのDSL(ドメイン固有言語)であるcuTile Pythonにおいて、言語サポートが大幅に強化されました。これにより、開発者はPython上でより高度なGPU制御を記述できるようになります。
- 再帰関数のサポート
- キャプチャ付きクロージャ(ネストされた関数やラムダ関数)のサポート
- カスタムのリダクションおよびスキャン関数
- 型注釈(タイプアノテーション)付きの代入
- 部分配列のビューを作成する
Array.sliceなど、配列サポートの強化
また、システム全体へCUDA Toolkitをインストールすることなく、以下のようなシンプルなpipコマンドでcuTile Pythonと必要な依存関係をインストールできるようになりました。
pip install cuda-tile[tileiras]
コア機能のアップデート
CUDA 13.2では、メモリ管理やWindowsプラットフォームにおける動作、組み込み環境向け機能など、基礎的な部分で多数の拡張が行われています。
より柔軟なメモリ転送:属性付きmemcpy API
以前のCUDA 12.8で導入されたバッチ処理用のmemcpy APIに加え、単一のメモリ転送に対してより簡単に属性を指定できる新しいAPI関数、cudaMemcpyWithAttributesAsync および cudaMemcpy3DWithAttributesAsync が追加されました。
これにより、複雑なバッチインターフェースを使用せずに転送を最適化できます。また、既存の cudaMemcpyAsync もオーバーロードされ、同じ引数リストで属性を利用可能になっています。
Windows環境でのメモリ削減とドライバモデルの変更
- LMEMフットプリントの削減: GPU上のローカルメモリ(LMEM)はスレッドごとに割り当てられますが、CUDA 13.2とCUDAドライバR595以降を組み合わせたWindows WDDMモードにおいて、このLMEMの使用量が大幅に削減されました。これにより、メモリ制約の厳しいvGPU環境などでメリットが得られます。
- デフォルトドライバモードのTCCからMCDMへの移行: 互換性のあるWindowsシステムでは、これまでデフォルトでTCCモードで起動していたGPUが、MCDM(Microsoft Compute Driver Model)で起動するようになります。これにより、OSの機能との競合で起動時にデバイスマネージャーに警告マークが表示される問題が解消されます。MCDMへの移行により、WSL2上でのネイティブコンテナ実行や、高度なメモリ管理API(
cuMemCreate等)、RDMAのサポートなど、これまでWDDMに限定されていた機能が利用可能になります。
パフォーマンス制御と最適化機能
- メモリープールのプロパティクエリ:
cudaMemPoolGetAttributeAPIを使用し、既存のメモリープールのプロパティを取得できるようになりました。これを活用して、CUDA Graphsなどで同じプロパティを持つ新しいプールを簡単に作成できます。 - 省電力化(CUDA_DISABLE_PERF_BOOST): CUDAアプリケーション実行時にGPUがデフォルトで高い電力状態(ブースト)に移行するのを防ぐ環境変数
CUDA_DISABLE_PERF_BOOSTが追加されました。NVENC/NVDECなどを多用する環境で電力の節約が期待できます。 - CUDA Graphsのパラメータ取得: 構築されたグラフノードのパラメータを取得するためのポリモーフィック関数
cudaGraphNodeGetParamsが追加されました。
コンパイラと組み込みデバイス(Jetson)向け拡張
Visual Studio 2026のサポートや、gcc向けのARM C Language Extensionサポートが追加されました。また、サーバークラスと組み込みデバイス(NVIDIA Jetson Thorなど)の統合が進み、Jetson Orinを含むすべてのArmターゲットで同じArm SBSA CUDA Toolkitが利用可能になりました。
さらに、Jetson Thor向けにNVIDIA MIG(Multi-Instance GPU)がサポートされました。これにより、1つのGPUを完全に分離された2つのインスタンスに分割できます。ロボティクスなどの分野において、厳格なレイテンシが求められる「安全性が重視されるタスク(モーター制御等)」と「高負荷な処理(AIの知覚や言語モデル等)」を干渉させずに同時に実行可能になります。
数学ライブラリ(cuBLAS / cuSOLVER)の強化
シミュレーションやレンダリング等の計算基盤となる数学ライブラリも大きく強化されています。
NVIDIA cuBLAS:Blackwell向けMXFP8サポート
実験的なAPIであるGrouped GEMM(行列積)において、NVIDIA Blackwell GPU向けのMXFP8サポートが追加されました。
CUDA Graphsと組み合わせることで、ホストの同期を必要としないデバイス側での形状計算が可能になり、特定のAI(Mixture of Experts)ユースケースではマルチストリーム実装に比べて最大4倍の高速化を実現します。
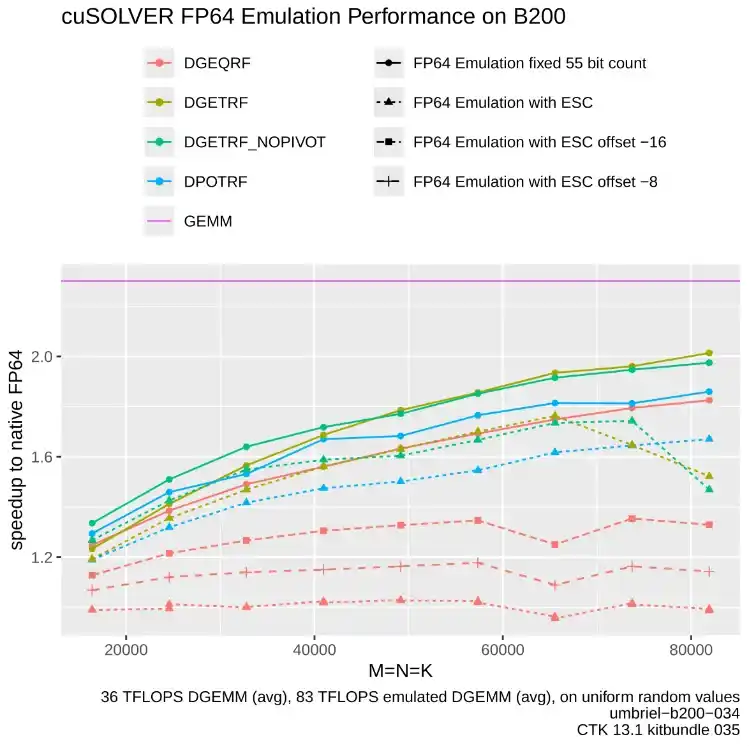
NVIDIA cuSOLVER:FP64エミュレーションによる高速化
INT8(8ビット整数)の処理能力が非常に高い最新のプラットフォーム向けに、FP64(倍精度浮動小数点)をエミュレートして計算を行う cuSOLVERD API が導入されました。このエミュレーション手法により、計算負荷の高いQR分解、LU分解、コレスキー分解において、パフォーマンスが大幅に向上します。
開発者ツールのアップデート
デバッグやプロファイリングを行うためのツール群も充実しています。
NVIDIA Nsight Python
Python開発者向けに、NVIDIAのプロファイリングツールを直接利用できる新しいカーネルプロファイリングインターフェースが提供されました。簡単なデコレータ(@nsight.analyze.plot など)を付与するだけで、Pythonフレームワーク経由で起動されたCUDAカーネルのパフォーマンスを測定・可視化できます。
@nsight.analyze.plot("02_paramater_sweep.png") @nsight.analyze.kernel(configs=sizes, runs=10) def benchmark_matmul_sizes(n: int) -> None: """異なるサイズで行列の乗算をベンチマークします。""" a = torch.randn(n, n, device="cuda") b = torch.randn(n, n, device="cuda") with nsight.annotate("matmul"): _ = a @ b
Numba-CUDAのデバッグ対応
これまで困難だった、GPU上で実行されるNumba-CUDAカーネルのデバッグが初めて可能になりました。CUDA-GDB(コマンドライン)および Nsight Visual Studio Code Edition を使用して、ブレークポイントの設定やプログラムのステップ実行が行えます(現在は初期サポート段階)。
NVIDIA Nsight Compute & その他のツール
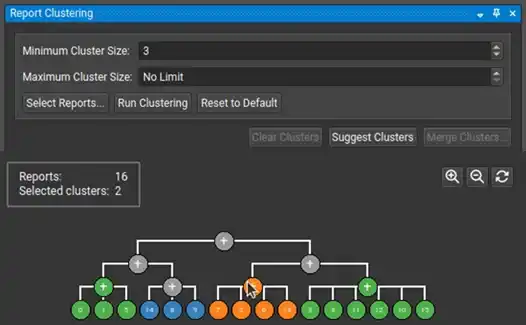
Nsight Compute 2026.1 には、複数のプロファイリングセッションやマルチプロセスアプリケーションのデータを整理するためのレポートクラスタリングおよびマージツールが新たに追加されました。また、ソース行の依存関係を特定するレジスタ依存関係の相関ウィンドウも実装されています。
その他、Kubernetes環境向けの Nsight Cloud の更新や、NVIDIA Developerアカウントがあれば無料で利用できるAIコーディングアシスタント Nsight Copilot、PyTorchのプロファイリングが改善された Nsight Systems のアップデートなどが含まれています。
CCCL 3.2 (CUDA Core Compute Libraries) とモダンなCUDA C++
CUDA 13.2には、CCCL(CUDA Core Compute Libraries)のバージョン3.2が同梱されています。これにより、C++開発者はより現代的で安全なインターフェースを利用できるようになります。
モダンなCUDA C++ランタイムAPI
cudaMalloc や cudaStreamCreate といった従来のC言語ライクなAPIに代わり、生産性と安全性を向上させるためのC++らしいイディオマティックなインターフェースが導入されました。
cuda::stream,cuda::eventなどのコアコンセプトを表す型- メモリリソースと
cuda::bufferによる簡単なメモリ管理 cuda::launchによる強力で簡便なカーネル起動
ベクトル加算の例:
cuda::device_ref device = cuda::devices[0];
cuda::stream stream{device};
auto pool = cuda::device_default_memory_pool(device);
int num_elements = 1000;
auto A = cuda::make_buffer<float>(stream, pool, num_elements, 1.0);
auto B = cuda::make_buffer<float>(stream, pool, num_elements, 2.0);
auto C = cuda::make_buffer<float>(stream, pool, num_elements, cuda::no_init);
constexpr int threads_per_block = 256;
auto config = cuda::distribute<threads_per_block>(num_elements);
auto kernel = [] __device__ (auto config, cuda::std::span<const float> A,
cuda::std::span<const float> B,
cuda::std::span<float> C){
auto tid = cuda::gpu_thread.rank(cuda::grid, config);
if (tid < A.size())
C[tid] = A[tid] + B[tid];
};
cuda::launch(stream, config, kernel, config, A, B, C);この例はCompiler Explorer上で実際に試すことができます。
新しい最適化アルゴリズム
- Top-K選択 (
cub::DeviceTopK): 入力全体をソートすることなく、最大(または最小)のK個の要素を抽出します。Kが小さいワークロードにおいて、完全な基数ソート(Radix Sort)と比較して最大5倍の高速化を実現し、メモリ消費も抑えられます。 - 固定サイズ・セグメントリダクション: 各セグメントのサイズが固定である場合に、オーバーヘッドを排除して計算を高速化する
cub::DeviceSegmentedReduceの新しいバリアントが追加されました。
// セグメントごとの開始/終了オフセットではなく、固定の segment_size を受け取る新しいAPI
cub::DeviceSegmentedReduce::Sum(d_temp, temp_bytes, input, output,
num_segments, segment_size);
- セグメントスキャンおよびバイナリサーチ: 新たな並列スキャン操作や、条件に一致する要素を早期退出ロジックで高速に検索する
cub::DeviceFind::FindIfなどが追加されています。
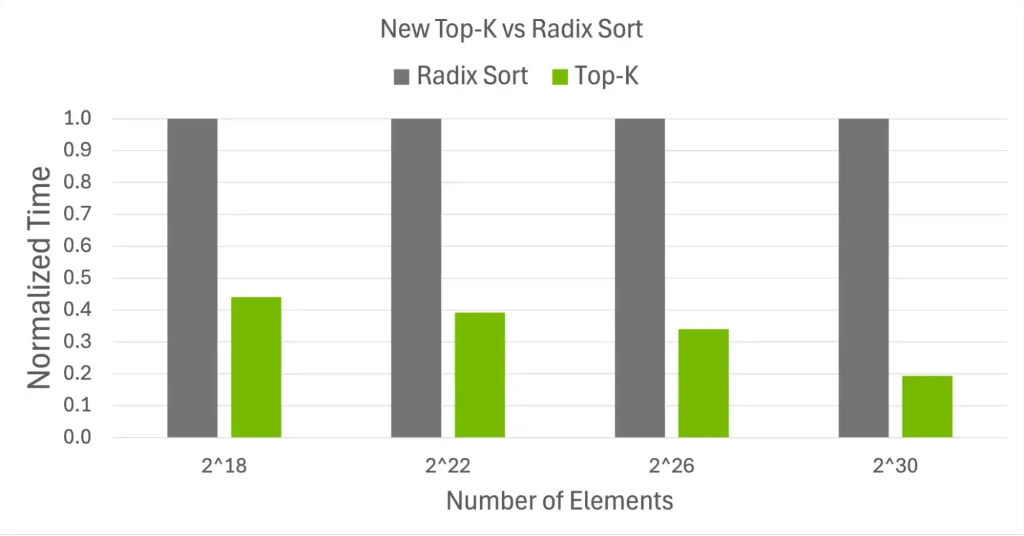
cub::DeviceTopK::MaxKeys と完全な基数ソートとの正規化された実行時間の比較CUDA Pythonの機能拡張
Python環境との統合もさらに深まっています。
- CuPyの対応と導入の簡略化: CuPyがCUDA 13.0および13.1をサポートしました。システム全体のCUDA Toolkitがなくとも
pip install cupy-cuda13xでインストール可能です。 - CUDA Stream Protocolの実装: PyTorchやJAXなどのフレームワークとCuPy間で、ストリームを直接共有できるようになりました。これにより、手動でのポインタ管理が不要なゼロコピーの相互運用が実現します。
# CuPyのストリームをPyTorchと共有するpytorch_stream = torch.cuda.ExternalStream(cupy_stream)# 外部のストリームをCuPyへインポートするcupy_stream = cupy.cuda.Stream.from_external(pytorch_stream)
- データ型とインデックスの拡張:
ml_dtypes.bfloat16のサポートが追加され、AIの学習や推論に用いられるネイティブな低精度計算がCuPyで可能になりました。また、コアオペレーションの最適化によりパフォーマンスが向上し、マルチスレッドのサポートも強化されています。CuPy配列はndarray.mdspanを介して、32ビット/64ビットのインデックス制御を持つcuda::std::mdspanオブジェクトとして扱うことが可能です。 - システム監視とバインディング:
cuda.core 0.6により、GPU監視・管理用のNVMLバインディング(cuda.bindings.nvml)やFat binary操作用のバインディング(cuda.bindings.nvfatbin)が導入されました。新設のcuda.core.systemモジュールを通じて、デバイスの温度監視やCPU/GPUの親和性(アフィニティ)などのシステム情報へPythonicにアクセスできます。 - PythonでのCUDA Graphs構築: 処理のシーケンスをキャプチャして再実行するCUDA Graphsの機能が、メインの
cuda.core名前空間で安定版として提供されるようになりました。条件分岐(ifやwhile)やフォークジョインなどの高度なパターンもサポートされます。
# オペレーションをキャプチャしてグラフを構築gb = device.create_graph_builder() gb.begin_building()# グラフ内にカーネルの起動をキャプチャ(まだ実行はされない)launch(gb, LaunchConfig(grid=256, block=256), kernel_a, data_ptr) launch(gb, LaunchConfig(grid=256, block=256), kernel_b, data_ptr) launch(gb, LaunchConfig(grid=256, block=256), kernel_c, data_ptr)# 構築を終了しグラフをインスタンス化graph = gb.end_building().complete()# 既存のCUDAストリームにグラフを起動graph.launch(stream)
まとめ
CUDA 13.2は、最新のGPUアーキテクチャのポテンシャルを引き出すだけでなく、Pythonをファーストクラスの言語として扱い、C++の記述をよりモダンにするなど、開発者の生産性を大きく向上させるリリースとなっています。
3DCGやシミュレーション分野においても、最適化されたメモリ転送APIや数学ライブラリのエミュレーション機能、効率的なアルゴリズム(Top-K抽出など)は、物理演算やレンダリングパイプラインの高速化に直接的な恩恵をもたらすでしょう。
さらに詳細な情報やツールのダウンロードについては、CUDA 13.2 Toolkitの公式ダウンロードページやNVIDIAのドキュメントをご参照ください。
CUDA 13.2 Introduces Enhanced CUDA Tile Support and New Python Features


コメント