
Nvidia が発表した、テキストから画像を生成する新しいAIモデル『 eDiff-I: Text-to-Image Diffusion Models with Ensemble of Expert Denoisers 』の紹介です。
eDiff-I について
eDiff-Iは新世代のジェネレーティブAIコンテンツ作成ツールで、テキストからの画像生成、即時のスタイル変換、そしてワードによる直感的なペイント機能を提供します。
diffusion modelでは、ランダムなノイズから徐々に画像を生成するノイズ除去を繰り返しながら、画像合成を行います。下図では、完全なランダムノイズから何段階ものノイズ除去を経て、最終的にパンダが自転車に乗っている画像を生成しています。
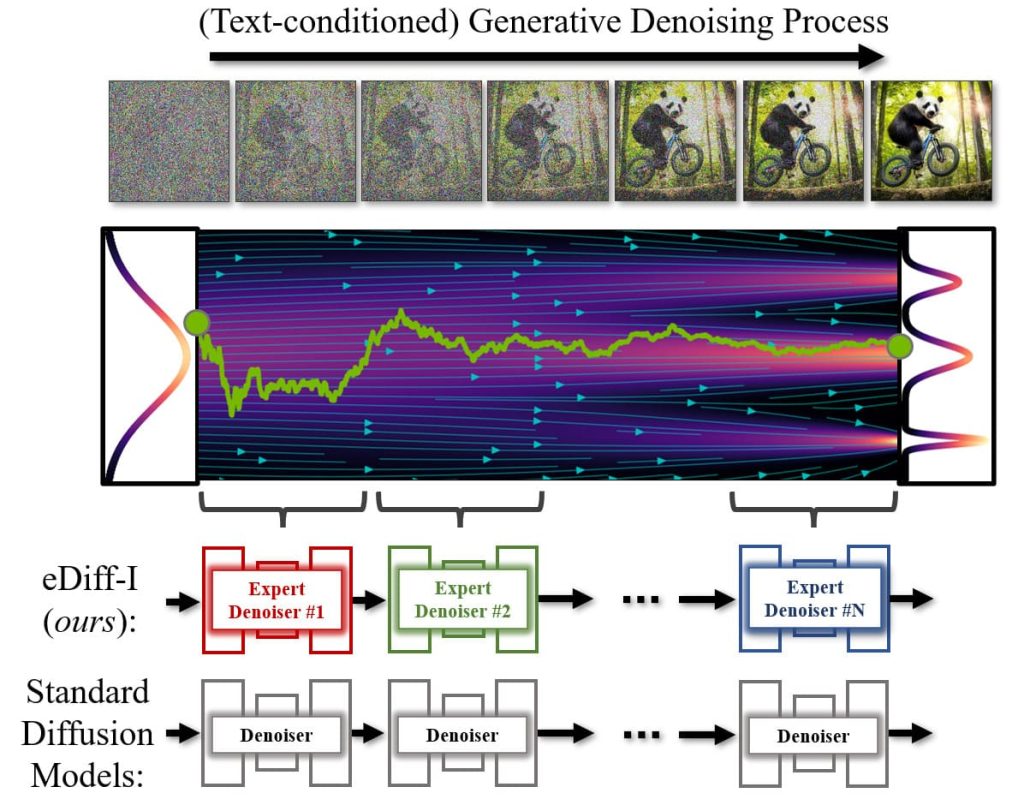
従来のdiffusion modelの学習では、1つのモデルでノイズ分布全体をノイズ除去するように学習していましたが、このフレームワークでは、生成過程の異なる区間でのノイズ除去に特化したExpert Denoiserのアンサンブルを学習させることで、生成過程の異なる区間でのノイズ除去を行います。このような Expert Denoiser を用いることで、合成能力を向上させることができます。
比較
オープンソースのテキストから画像への変換手法(Stable diffusion)と(DALL-E2)と比較し、このモデルは、合成品質を向上させことができており、よりプロンプトに忠実な結果を得られることがわかっています。

スタイル変換(Style transfer)
このメソッドは、CLIP画像埋め込みを利用することで、スタイル変換を可能にします。
まず、スタイル参照画像から、スタイル参照ベクトルとして利用可能なCLIP画像埋め込みを抽出します。下図の左側がスタイル参照画像です。中段のパネルは、スタイルコンディショニングを有効にした場合の結果を示しています。右側のパネルは、スタイル・コンディショニングを無効にした場合の結果です。スタイルコンディショニングを使用すると、入力スタイルと入力キャプションの両方に忠実な出力が生成されます。また、スタイルコンディショニングを行わない場合は、自然なスタイルで画像を生成しています。

ワードによる直感的なペイント機能(Paint with words)
このメソッドでは、プロンプトに記載されたフレーズを選択し、画像に書き込むことで、プロンプトに記載されたオブジェクトの位置をユーザが制御することができます。そして、モデルはプロンプトとマップを利用して、キャプションと入力マップの両方に整合性のある画像を生成します。
他にも、この手法では、入力キャプションで指定された様々なスタイルの画像を生成することもできます。


また、Nvidiaは以前からテキストから画像を生成する機能を研究しデモなどを公開しており、今のところNvidiaのツールには組み込まれていませんが、将来的には、NVIDIA Canvas に追加されるかもしれません。
『 eDiff-I: Text-to-Image Diffusion Models with Ensemble of Expert Denoisers 』ページへ


コメント