
ここひと月ほどでComfyUIの多くの更新が行われました。この記事では、ComfyUI で最近行われたアップデートを紹介したいと思います。
以下のアップデート内容はv0.3.51からv0.3.57の内容となります。
Qwen Image ControlNet サポート
構造に基づいた画像生成のため、Qwen-Imageが複数のControlNetモデルに対応しました。
- Qwen-Image DiffSynth ControlNets model patch:canny、depth、inpaintをサポート。
- Qwen-Image Union DiffSynth LoRA: lineart、softedge、normal、openposeをサポート。
- InstantX Qwen ControlNet :InstantXのQwen用ControlNetに対応しました。
詳しい情報は以下の記事をご覧ください。

Qwen ImageとLoRAの連携
Qwen ImageがLoRAに対応し、Qwen-Imageのワークフローに「LoRA Loader」ノードを追加するだけで、3Dボクセル風や90年代レトロアニメ風など、様々なスタイルを手軽に適用できるようになりました。

新しいモデル対応
Wan2.2 S2V
「Wan2.2 S2V(Speech to Video)」は、一枚の画像と音声クリップから、高品質で表現力豊かなキャラクタービデオを生成できる高度な音声駆動ビデオ生成モデルです。
この技術は、漫画や動物など多様なキャラクターに対応しており、音声を元に、対話、歌、パフォーマンスなど、さまざまなクリエイティブなニーズに対応し、生き生きとした細やかな表情や体の動きを生成することができます。

Qwen image edit
Qwen-Image-Editは、Qwen-Imageの画像編集バージョンです。
20B(200億)パラメータを持つQwen-Imageモデルを基に追加学習を行い、Qwen-Image独自のテキストレンダリング能力を編集タスクに拡張することに成功し、高精度なテキスト編集が実現されています。
Qwen-Image-Editは入力画像をQwen2.5-VL(視覚的な意味制御用)とVAEエンコーダー(視覚的な外観制御用)の両方に入力することで、意味論と外観のデュアル編集能力を達成しています。

WAN 2.2 Fun
Wan2.2 Funは、AlibabaのAI開発プラットフォーム(PAI)チームによって開発された、オープンソースの動画生成モデル群です。「Fun」が単一のモデルではなく、基盤となるWan2.2アーキテクチャ上に構築された、特定の機能に特化したツールスイートを指します。
Fun Control、Fun InPでは、単なるテキストプロンプトからの動画生成(Text-to-Video)を超え、より意図的かつ監督的な映像制作が可能になります。

ByteDance USO
2025年9月4日、ByteDance社が開発した新しい画像生成モデル「USO (Unified Style-Subject Optimized)」が、画像生成AIのUIである「ComfyUI」でネイティブサポートされました。
USOは、画像のスタイル(画風)とサブジェクト(被写体)の両方を高精度に制御できるモデルで、FLUXアーキテクチャをベースに構築されています。
USOモデルの主な特徴
- 統合されたフレームワーク: これまで別々だった「スタイル(画風)の転送」と「サブジェクト(被写体)の一貫性」を初めて1つのモデルで実現。
- 3つの生成モード: サブジェクトを重視するモード、スタイルを重視するモード、そしてその両方を組み合わせたモードを使い分けることができます。
- 柔軟な制御: 複数の画風を混ぜ合わせたり、元の画像の構図を維持したり、あるいは変更したりといった高度な制御が可能です。
ComfyUIを最新版にアップデート後、サイドバーのテンプレートから「Flux.1 Dev USO Reference Image Generation」を選択することで、ガイドに従ってモデルをダウンロードし、利用を開始できます。
EasyCacheによる高速化
「EasyCache」と「LazyCache」が導入され、画質とのバランスを取りながら生成速度を向上させることが可能になりました。
この技術は、ノイズ除去プロセスにおけるサンプリングステップを戦略的に省略することで、視覚的な鮮明さを多少犠牲にしつつ、画像生成を高速化する技術です。速度と視覚的な忠実度のトレードオフを、1つのパラメータで制御できます。
TeaCacheなどの他の手法と比較して、モデルに合わせて最適化するためのハイパーパラメータセット必要とせず、サポートされるモデルの種類ごとにコードを変更する必要もありません。
これにより、今後導入されるすべてのモデルに即座に対応することが可能となります。


コンテキストウィンドウのサポート
長いシーケンス(動画など)の生成に対応するため、「Context Windows (Manual)」と「WAN Context Windows (Manual)」ノードが追加されました。

これらのノードを使うと、長いシーケンスを一度に処理するのではなく、スライディング式のコンテキストウィンドウで分割してサンプリングできるようになります。これにより、メモリ(VRAM)の消費を抑えつつ、一貫性を保った長いコンテンツを生成しやすくなります。
現在は手動操作のみ対応しており、一部の WAN モデルはまだ調整が必要ですが、これは今後の高度なスケジューリングやカスタムノードの基盤となります。

NVIDIA Blackwell GPUでの推論速度向上
Windows環境において、NVIDIAの次世代GPU「Blackwell(50シリーズ)」での動作が約20%高速化されました。
無制限の並列APIノードと新モデル対応
APIノードは、外部APIサービスに接続する特別なノードのセットです。これにより、クローズドソースまたはサードパーティがホストするAIモデルをComfyUIワークフローで直接利用できるようになります。
これらのノードは、ComfyUIのコア部分のオープンソース性を維持しながら、外部モデルの機能をシームレスに統合するように設計されています。クローズドソース モデルへの API 呼び出しにクレジットが必要なので有料となります。詳しい利用方法はこちらから
APIノードの並列使用が無制限に
ComfyUI APIノードが大幅に強化され、複数のAPI呼び出しを同時にトリガーできるようになりました。これにより、創造的なアイデアを最速でテストし、検証できます。
Run unlimited API nodes in parallel — no more waiting, test endless ideas instantly!
— ComfyUI (@ComfyUI) August 22, 2025
New APIs now live in ComfyUI:
🔹 MiniMax Hailuo-02
🔹 Vidu
🔹 Kling 2.1
🔹 Veo 3 & Veo 3 Fast
🔹 GPT-5
🔹 Gemini 2.5 pic.twitter.com/XQaHLrsGp2
Nano-banana (Gemini-2.5-Flash Image) サポート開始!
Gemini-2.5-Flash Image 通称「Nano-banana」がネイティブAPIノードを通じてサポートされました。
これにより、最先端の画像生成機能をワークフローに直接組み込むことができます。

モデルの特長
- キャラクターの一貫性と忠実性において優れた性能
- テキストからの画像生成と画像からの画像生成の両方をサポート
- 画像と同時にテキスト出力も可能
- 解像度とアスペクト比のカスタマイズが可能
次のライブストリームでは、nano banana と Wan 2.2 を活用した動画の作成ワークフローを見ることができます。
新しいAPIモデルとワークフロー例
さらに、以下の最新モデルがAPIノードで利用可能になりました。
MiniMax Hailuo-02 Video
このモデルは、特に高解像度の動画生成に焦点を当てています。具体的な出力オプションとして、以下の2つのモードが提供されています。
- 768p解像度: 6秒または10秒の長さの動画を生成できます。
- 1080p解像度: より鮮明な6秒間の動画を生成することが可能です。
Vidu Video Generation
Viduは多様な入力形式に対応しており、ユーザーの創造性を広げる4つの主要な生成モードを持っています。
- テキストから動画へ (Text-to-Video): プロンプト(テキスト指示)を基に、情景を動画として生成します。
- 画像から動画へ (Image-to-Video): 1枚の静止画に動きを加えてアニメーション化します。
- 参照から動画へ (Reference-to-Video): スタイルやキャラクターの参考となる画像を基に、その特徴を反映した動画を生成します。
- 開始・終了フレームから動画へ (Start-End to Video): 動画の最初と最後のフレームを指定すると、その間の動きをモデルが自動的に補完して生成します。
Veo 3
このモデルには2つのバージョンがあり、それぞれ音声の有無を選択できます。
- veo3: 標準バージョンです。
- veo3-fast: より高速な生成が可能なバージョンです。
OpenAI Chat (GPT-5ファミリー)
用途に応じて最適化された3つのモデルが提供されており、ユーザーは目的に合わせて選択できます。
- gpt-5: シリーズの中で最もパワフルで、最高峰の推論能力と生成能力を持ちます。
- gpt-5-mini: より軽量な計算処理で、高速な応答を実現するモデルです。
- gpt-5-nano: 非常に軽量で、素早いやり取りや効率的なタスク処理に適しています。
Google Gemini (2.5シリーズ)
Googleの最新世代モデルも利用可能で、それぞれ異なる強みを持っています。
- gemini-2.5-pro: 高度な推論能力が求められる複雑なタスクに適しています。
- gemini-2.5-flash: 速度と迅速な反復作業に最適化されています。
UI/UXの大幅改善
v0.3.51では、6月以来最大規模となるフロントエンドのアップデートが行われ、ワークフローの構築と管理がさらに快適になりました。
サブグラフ (Subgraph)
サブグラフ機能が安定版で正式に利用可能になり、メイングラフ上の元のノードに解凍できるようになりました。
サブグラフは、ワークフローの再利用可能なモジュールとなり、簡単にコピーして貼り付けることが可能です。

新しいマネージャーUI
カスタムノードを管理する「Manager」のUIが再設計され、より使いやすくなりました。
上部バーの「Manager Extension」をクリックすると、再設計されたUIにアクセスできます。
ミニマップ
広大なキャンバスを簡単に移動できる「ミニマップ」機能も追加されました。キャンバス内のナビゲーションが簡単になりました。
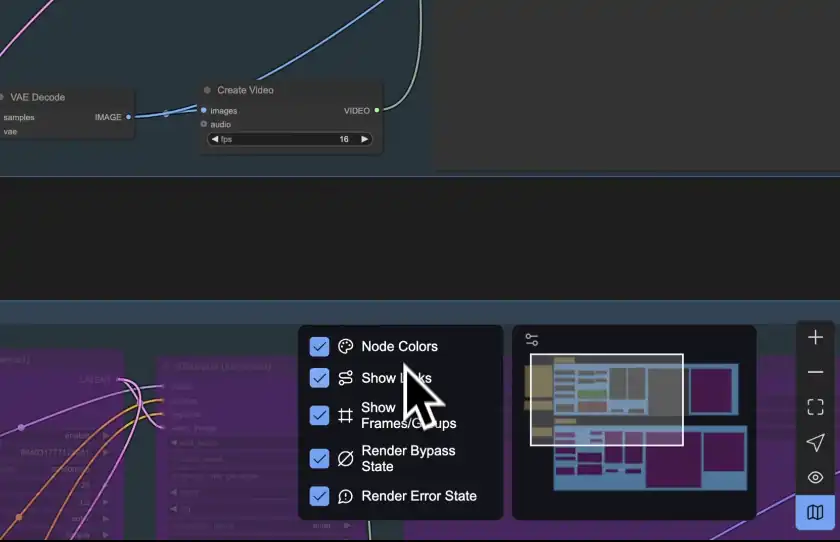
その他のUI改善
- 標準ナビゲーションモード: マウスホイールでのスクロールに対応。設定でいつでも従来のズームモードに戻すことができます。
- タブプレビュー: タブを切り替えずに内容を確認可能に。
- ショートカットパネル: 全てのショートカットを一覧表示できるようになりました。変更内容はリアルタイムで更新されます。
- ヘルプセンター: アプリ内で直接、変更履歴を確認可能に。
ComfyUI 0.3.51: Our biggest frontend update since June ✨
— ComfyUI (@ComfyUI) August 21, 2025
What’s new:
🔹 Subgraph officially in stable releases
🔹 The new Manager UI
🔹 Mini Map navigation
🔹 Tab previews + Shortcut panel
🔹 Standard navigation mode
🔹 Help Center with changelogs pic.twitter.com/BdgEboFKnN
その他の新機能 (v0.3.51 – v0.3.57)
新しいノードの追加
- ImageScaleToMaxDimension (v0.3.57): 画像を指定した最大寸法に収まるようにスケーリングするノードが追加されました。
- WanSoundImageToVideoExtend (v0.3.55): 音声から生成されたビデオ(S2V)を手動で延長するためのノードが追加されました。
- LatentCut (v0.3.55): 潜在表現(Latent)の一部を切り出すためのノードが利用可能になりました。
- LatentConcat (v0.3.53): 複数の潜在表現を連結するためのノードが導入されました。
- FluxKontextMultiReferenceLatentMethod (v0.3.51): Fluxモデルで複数の参照潜在表現を利用するためのノードが追加されました。
- Record Audio (v0.3.51): マイクなどから音声を録音できるノードが利用できるようになりました。
新モデルとエンコーダーのサポート
- USOモデルの機能拡張 (v0.3.57): サブジェクト(被写体)の一貫性を保つためのLoRAや、スタイル参照機能が実装されました。
- ByteDance Image API Node (v0.3.57): ByteDanceの画像生成モデルを利用するためのAPIノードが追加されました。
- Ideogram Character API Node (v0.3.57): Ideogram APIにキャラクターの一貫性を保つための機能が追加されました。
- Wan2.2 5B Fun Control/Inpaint Model (v0.3.55): Wan 2.2の5Bパラメータを持つControlモデルとInpaintモデルが新たにサポートされました。
- Wan 2.2 S2V Model (v0.3.53): Wan 2.2のSound-to-Videoモデルに対応しました。
- wav2vec2 Audio Encoder (v0.3.53): オーディオエンコーダーとして`wav2vec2`が利用できるようになりました。
- Qwen Image Edit Model (v0.3.51): Qwenの画像編集モデルが利用可能になりました。
- APIノードにKling v2.1追加 (v0.3.51): APIノードに、Klingビデオモデルの`v2-1`と`v2-1-master`が追加されました。
- wan2.2 Camera Model (v0.3.51): `wan2.2`のカメラモデルがサポート対象になりました。
新しいサンプラーの追加
- DPM++ 2M SDE Heun (RES) (v0.3.53): 新しいサンプラーとして「DPM++ 2M SDE Heun (RES)」が追加され、利用可能になりました。
機能改善とパフォーマンス向上
- 畳み込みオートチューニングの有効化 (v0.3.57): パフォーマンス向上のため、畳み込み演算のオートチューニングが有効になりました。
- SEEDSのノイズ分解が更新 (v0.3.57): SEEDS機能に関するノイズ分解の更新とリファクタリングが行われました。
- WindowsでのRAM使用量削減 (v0.3.56): Windows環境でのメモリ効率が改善され、RAM使用量が削減されました。
- 音声の自動トリミング (v0.3.55): 動画を保存する際、映像の長さに合わせて音声が自動的にトリミングされるように改善されました。
- S2Vのパフォーマンス改善 (v0.3.53): 120フレームを超えるSound-to-Video生成時のパフォーマンスが向上し、メモリ見積もりの精度も高まりました。
- ポータブル版のファイルサイズ削減 (v0.3.51): ポータブル版(Windows)のファイルサイズがさらに削減され、より扱いやすくなりました。
- SDPAバックエンドの優先度設定 (v0.3.51): Scaled Dot Product Attention (SDPA) バックエンドの優先順位が設定されるようになりました。
- PyTorch旧バージョンとの互換性向上 (v0.3.51): 古いPyTorchバージョンでのクラッシュやグラフブレークが回避され、使用時には警告が表示されるよう改善されました。
- Qwenモデルの互換性向上 (v0.3.51): Qwen VLのRope修正や埋め込み精度問題の修正により、参照コードとの互換性が向上しました。
その他
- Python 3.13のサポート (v0.3.52): 最新のPythonバージョンである3.13が正式にサポートされるようになりました。
- XPU iGPUのリグレッション修正 (v0.3.51): Intel GPU環境で発生していたリグレッション(機能低下)が修正されました。
- Moonvalleyビデオノードのパラメータ更新 (v0.3.51): Moonvalleyビデオノードのデフォルトパラメータが更新されています。
- WANノードのV3スキーマ変換 (v0.3.51): 内部的な改善として、WAN関連ノードが新しいV3スキーマに変換され、将来の拡張性が高められました。
- 各種ノードのV3スキーマ変換 (v0.3.57): Stable Cascade, Video, Primitive, Runway API, AlignYourStepsSchedulerなど、多数のノードが将来の拡張性を見据えたV3スキーマに変換されました。
- などなど
Qwen Image ControlNet & LoRA, EasyCache and Context Window in ComfyUI
ComfyUI 0.3.51: Subgraph, New Manager UI, Mini Map and More


コメント