2025年11月19日(現地時間) – Metaは、次世代の画像・動画理解モデル「Segment Anything Model 3 (SAM 3)」を発表しました。
SAM 3とは
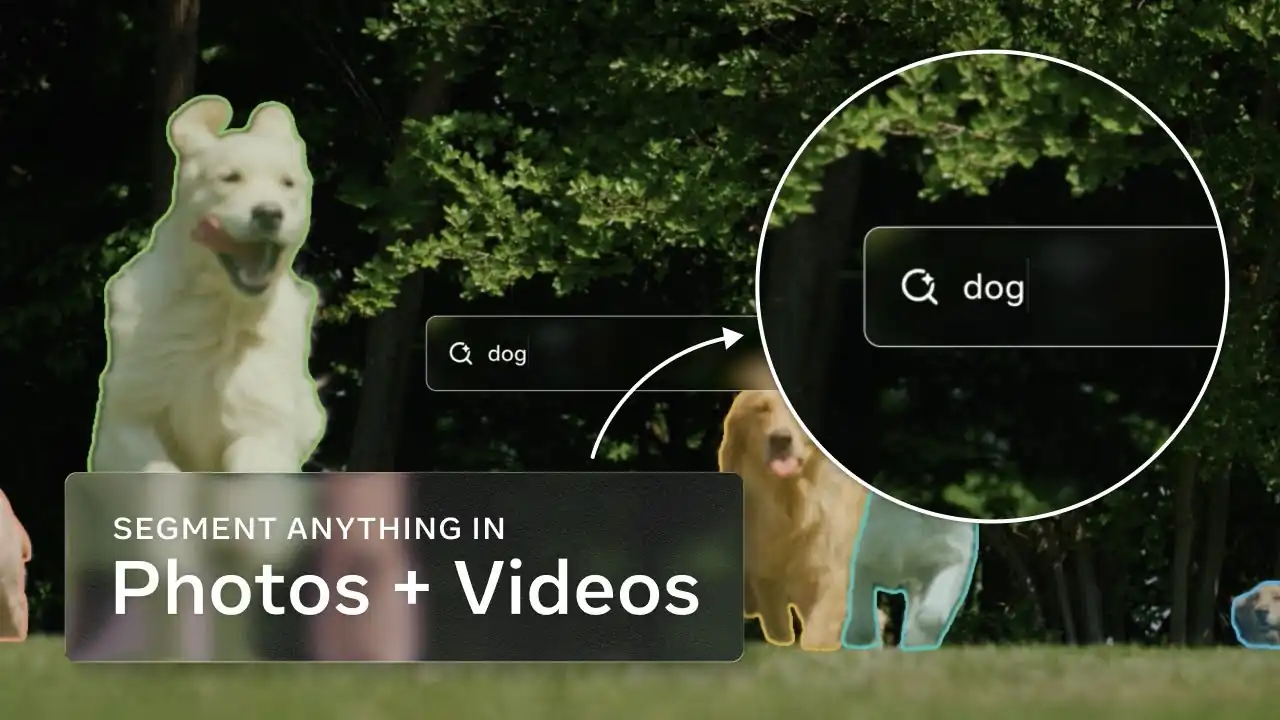
テキストや視覚的プロンプトを用いて、画像や動画内のあらゆる概念を検出し、分割し、追跡できる統合モデルです。
このモデルは、画像および動画の理解をさらに推し進めるもので、以前から要望の多かった「テキストおよび例示(Exemplar)プロンプト」機能が導入されています。
従来のコンピュータビジョンモデルでは、言語を画像内の特定の視覚要素に結びつけることが大きな課題でした。多くのモデルは固定されたテキストラベルのセット(例:「人」「車」など)に依存しており、「赤い縞模様の傘」のようなニュアンスを含む、リストにない概念を扱うことが困難でした。
SAM 3はこの制限を克服するため、短い名詞句(オープン語彙)や画像の例示をプロンプトとして受け付けることで、固定ラベルに縛られる制約をなくしました。また、SAM 1やSAM 2で導入されたマスク・ボックス・ポイントといった視覚的プロンプトにも対応し続けています。
データエンジンの構築
多様なカテゴリーや視覚ドメインをカバーする高品質なアノテーションデータ(セグメンテーションマスクとテキストラベル)を取得することは、非常に困難でコストがかかります。Web上にはこの種の大規模データは存在せず、特に動画内の全オブジェクトを網羅的にマスクすることは、人間にとって極めて時間のかかる作業です。
Metaはこの課題に対し、SAM 3、人間のアノテーター、そしてLlamaなどのAIモデルをループに組み込んだスケーラブルなデータエンジンを構築しました。
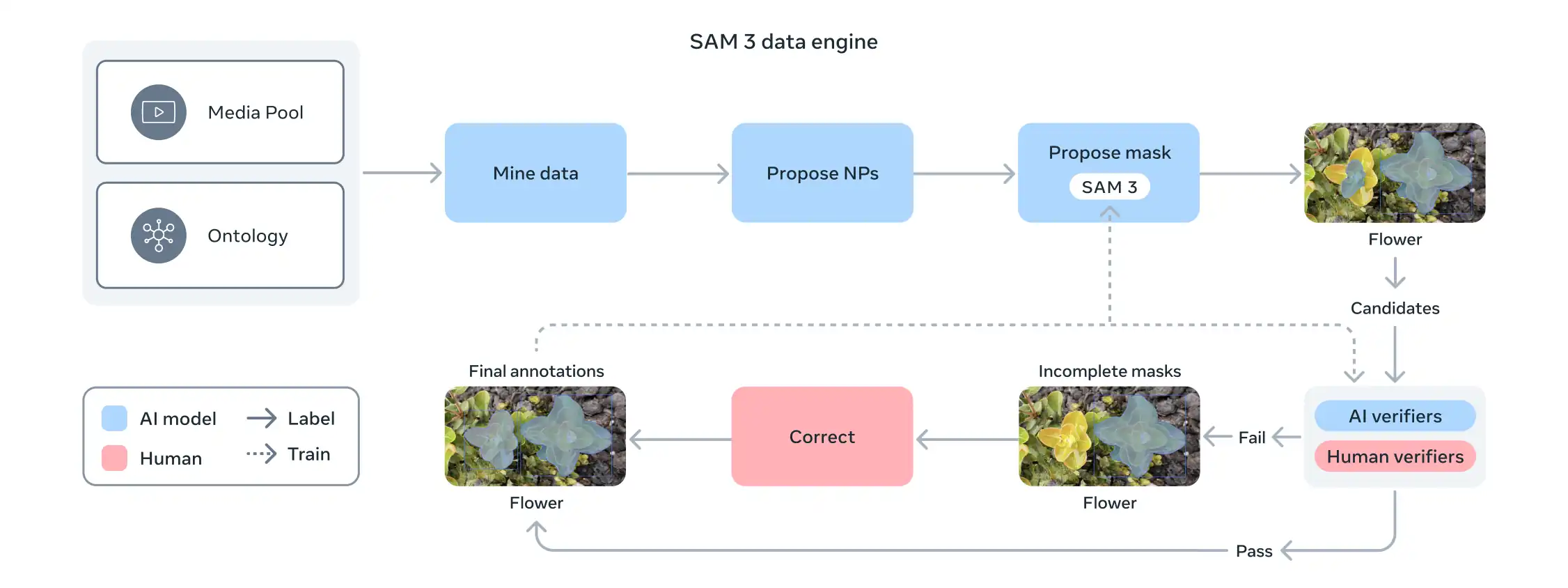
- 自動生成: AIパイプラインが画像・動画をマイニングし、キャプションを生成・解析して初期マスクを作成します。
- AIによる検証: Llama 3.2vベースのAIアノテーターが、マスクの品質や網羅性を検証します。これにより、簡単な例を自動的にフィルタリングし、人間の労力を難易度の高いケースに集中させます。
- 人間による修正: 最終的な検証と修正を人間が行い、そのフィードバックがモデルを改善します。
このシステムにより、ネガティブプロンプト(存在しない概念)の判定で人間の約5倍、ポジティブプロンプトでも36%の高速化を実現しました。結果として、400万以上のユニークな概念を含む大規模で多様なトレーニングセットが完成しました。
モデルアーキテクチャとパフォーマンス
SAM 3は、概念検出、セグメンテーション、追跡という異なるタスクを単一のモデルで解決するために設計されています。
タスク間の競合(例:追跡には個体を区別する特徴が必要だが、検出には概念ごとの共通特徴が必要)を解消するため、アーキテクチャは慎重に設計されました。
- Meta Perception Encoder: 4月に公開されたこのエンコーダを採用し、以前のエンコーダと比較して大幅な性能向上を実現しました。
- DETRベースの検出器: DETRを基盤としており、Transformerを用いた物体検出の先駆けとなった技術です。
- SAM 2ベースの追跡: SAM 2で導入されたメモリバンクとメモリエエンコーダを活用し、動画内での追跡を行います。
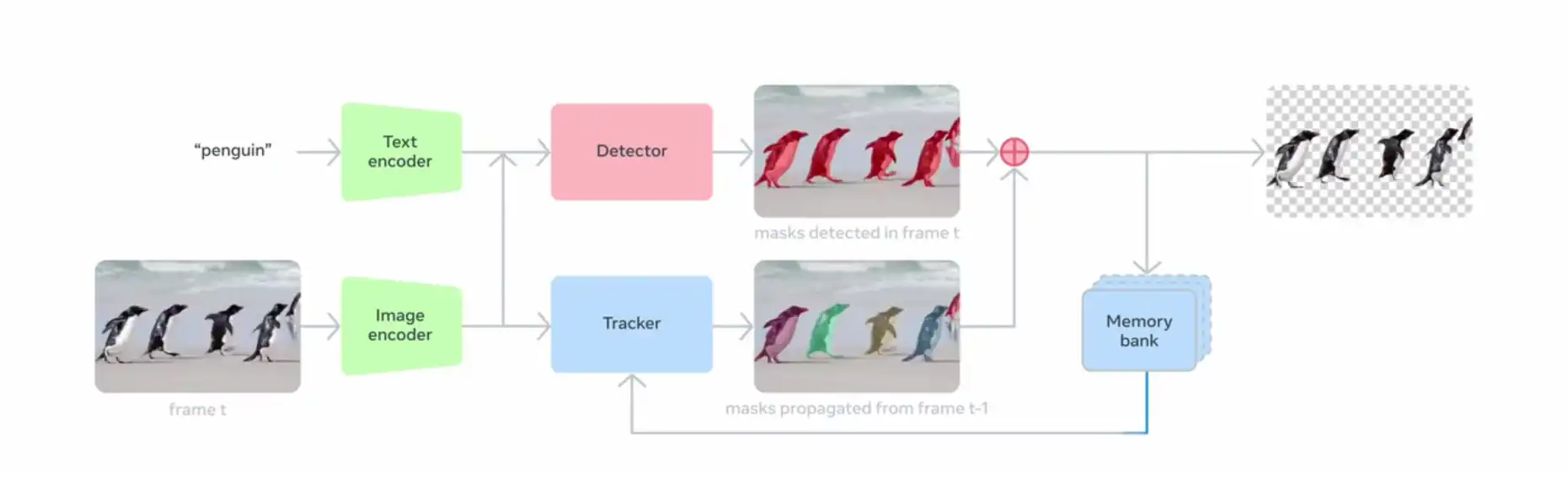
優れたベンチマーク結果を実現
SA-Coベンチマーク(画像および動画)において、SAM 3は既存のモデルと比較してcgF1スコアを2倍に向上させました。Gemini 2.5 Proのような基盤モデルや、GLEE、OWLv2といった専門モデルを一貫して上回っています。ユーザー調査でも、OWLv2と比較して約3対1の割合でSAM 3の出力が好まれています。
また、推論速度も高速で、H200 GPU上で画像1枚(100以上のオブジェクト検出)あたり30ミリ秒で動作します。動画においても、約5つのオブジェクトを同時に処理する場合、ほぼリアルタイムのパフォーマンスを維持します。

さらに、「SAM 3 Agent」と呼ばれるマルチモーダルLLMとSAM 3を組み合わせたツールは、「馬を制御・誘導するために使われる物体は何か?」といった複雑なテキストクエリにも対応可能です。
科学と実社会への応用
SAM 3はすでに科学分野でのユースケースに適用されています。
- 野生動物モニタリング: Conservation X LabsおよびOsa Conservationとの提携により、SAM 3を活用した「SA-FARI」データセットを構築しました。これは100種以上、1万本以上のカメラトラップ動画を含み、全ての動物にセグメンテーションマスクが付与されています。
- 海洋探査: FathomNetとの連携により、FathomNet Databaseを通じて水中画像向けのセグメンテーションマスクと新しいベンチマークを提供し、海洋研究コミュニティを支援しています。
また、Facebook Marketplaceの「View in Room」機能(SAM 3Dも使用)や、InstagramのEditsアプリ、Meta AIアプリの「Vibes」機能、ウェブ上のmeta.aiなど、Metaの製品群においてもクリエイティブな画像編集やAR体験を支える基盤技術として活用されています。
オープンソースコミュニティに向けた今後の探究領域
SAM 3は、画像や短い動画に対してシンプルなテキストフレーズを用いた物体セグメンテーションで高い性能を示していますが、Metaは、さらなる改善の余地もあるとしています。
課題と改善の方向性は以下の通りです。
- 専門領域の概念認識: SAM 3は「血小板」のような専門知識を要する細かな概念をゼロショットで一般化することが難しく、医療や科学分野の特殊な画像では性能が制限されます。ただし、少量のアノテーション付きデータでファインチューニングすると、新しい概念や領域に素早く適応できることが確認されています。今回のコード公開では、コミュニティが独自用途に合わせてSAM 3を適応できるファインチューニング手法も提供しています。また、Roboflowと連携し、データのアノテーションからファインチューニング、デプロイまでを支援する仕組みも整えています。
- 複雑なテキストプロンプトへの対応: SAM 3は「ハードカバーの本」のような短いオープン語彙プロンプトには強い一方で、「上段の右から2番目の本」のような長く複雑な記述には対応できません。ただし、マルチモーダル大規模言語モデルと組み合わせることで、推論を伴う複雑な記述にも対応できる可能性があります。
- 動画処理の効率化: 動画では、SAM 3はSAM 2と同様に「マスクレット」で各オブジェクトを追跡します。そのため、追跡対象の数に比例して推論コストが増加します。現在は各オブジェクトを独立して処理しており、相互の情報共有は行われていません。オブジェクト間のコンテキストを共有する仕組みを導入すれば、多数の類似オブジェクトが存在する複雑なシーンで効率性と性能をさらに高められると考えられます。
この分野にはまだ多くの研究課題が残されています。Metaは、AIコミュニティがSAM 3を活用し、SA-Coベンチマークを採用し、新しいリソースを利用することで、さらなる進歩を遂げられることを期待しているとのことです。
Segment Anything PlaygroundとAria
これらすべての成果を統合したのが、新しい「Segment Anything Playground」です。
技術的な専門知識がなくても、誰でもブラウザ上で画像や動画をアップロードし、SAM 3の機能を試すことができます。実用的な「顔のピクセル化」から楽しい「スポットライト効果」まで、様々なテンプレートが用意されています。
また、SAM 3はMetaのAria Gen 2研究用グラスで撮影された一人称視点の映像でも優れたパフォーマンスを発揮します。PlaygroundではAria Gen 2 Pilot Datasetの一部も体験可能で、ロボティクスや文脈AIへの応用可能性を示しています。
関連リソース・ダウンロード
今回のリリースでは、SAM 3のモデルチェックポイント、評価データセット、ファインチューニング用コードが公開されています。
さらに、この大規模な語彙認識能力を評価するために、Metaは新しいベンチマーク「SA-Co (Segment Anything with Concepts)」を作成し、GitHubで公開しました。これは、画像や動画におけるプロンプタブルな概念セグメンテーションのための新たな基準となります。
関連リソース・ダウンロード
公式の研究論文、コード、モデル、デモ体験へのアクセスは以下をご参照ください。
デモ体験 (Experience)
Segment Anything Playgroundで、ブラウザ上ですぐにモデルを試せます。
Introducing Meta Segment Anything Model 3 and Segment Anything Playground


コメント